Python NLTK学习2(FreqDist对象)
本系列博客为学习《用Python进行自然语言处理》一书的学习笔记。
频率分布
打开Python解释器,输入如下代码:
import nltk
from nltk.book import *
fdist1 = FreqDist(text1)
我们使用Text的实例对象作为参数生成了一个FreqDist对象,FreqDist继承自dict,所以我们可以像操作字典一样操作FreqDist对象。在本例中,FreqDist中的键为单词,值为单词的出现总次数。实际上FreqDist构造函数接受任意一个列表,它会将列表中的重复项给统计起来,在本例中我们传入的其实就是一个文本的单词列表。我们可以看看每个单词对应的出现次数:
for key in fdist1:
print(key, fdist1[key])
结果如下:
...
introduced 6
illustrates 1
pepper 2
independence 1
desirous 1
...
FreqDist::plot(n):该方法接受一个数字n,会绘制出现次数最多的前n项,在本例中即绘制高频词汇。
fdist1.plot(10)
结果如下:
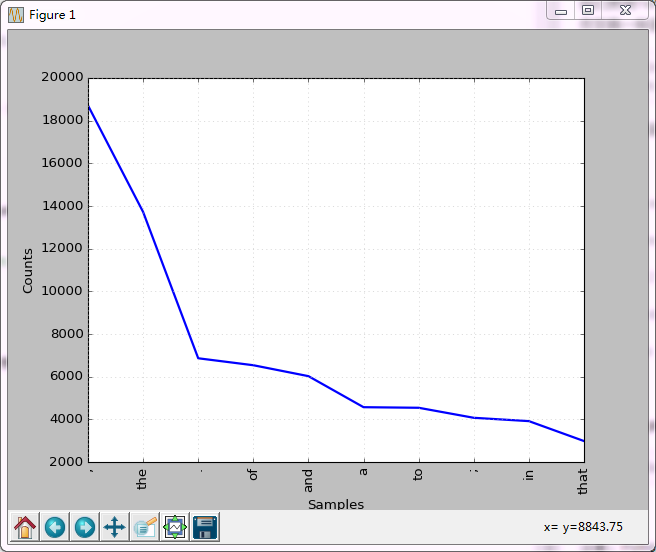
我们可以看到前10项的高频词,高频词大都是一些没意义词汇,如the、of、and等,他们大多是短单词。
FreqDist::tabulate(n):该方法接受一个数字n作为参数,会以表格的方式打印出现次数最多的前n项。
fdist1.tabulate(15)
结果为:
, the . of and a to ; in that ' - his it I
18713 13721 6862 6536 6024 4569 4542 4072 3916 2982 2684 2552 2459 2209 2124
FreqDist::most_common(n):该方法接受一个数字n作为参数,返回出现次数最多的前n项列表。
fdist1.most_common(15)
结果为:
[(',', 18713), ('the', 13721), ('.', 6862), ('of', 6536), ('and', 6024), ('a', 4569), ('to', 4542), (';', 4072), ('in', 3916), ('that', 2982), ("'", 2684), ('-', 2552), ('his', 2459), ('it', 2209), ('I', 2124)]
FreqDist::hapaxes(): 该方法会返回一个低频项列表,低频项即出现一次的项。
fdist1.hapaxes()
结果如下:
['whalin', 'comforts', 'footmanism', 'peacefulness', 'incorruptible', ...]
低频词也基本不会是文本的特征词汇。
FreqDist::max():该方法会返回出现次数最多的项。
print(fdist1.max())
结果为:
','
细粒度的选择词
长高频词一般为文本的特征词,我们可以看看文本中长度大于7个字符出现次数超过7次的词:
words = set(text1)
long_words = [w for w in words if len(w) > 7 and fdist1[w] > 7]
print(sorted(long_words))
结果如下:
['American', 'Atlantic', 'Bulkington', 'Canallers', 'Christian', 'Commodore', ...]
总结
FreqDist类
- 继承自dict
- 构造函数接受一个列表
- 键为传入构造函数的列表中的不同项,值为项出现的次数
FreqDist成员方法:
- plot(n),绘制出现次数最多的前n项
- tabulate(n),该方法接受一个数字n作为参数,会以表格的方式打印出现次数最多的前n项
- most_common(n),该方法接受一个数字n作为参数,返回出现次数最多的前n项列表
- hapaxes(),返回一个低频项列表
- max(),该方法会返回出现次数最多的项。
其他章节链接
Python NLTK学习2(FreqDist对象)




还没有人评论...